CV 系列的论文和程序得一点点开坑了。目前准备的计划任务是:FCN,OHEM,Mask RCNN,YOLO,Focal loss,Seesaw loss。别问,问就是网上一点点查阅得到的,然后写写代码。这个系列完结后,大概会结合对抗样本 and 目标检测做一些东西。自己还是差的太远。
什么是语义分割
语义分割的直观解释可以见下图,计算照片中的每一个像素点的类别,进而得到哪些像素点属于同一类,把一些物体给分割出来:

FCN
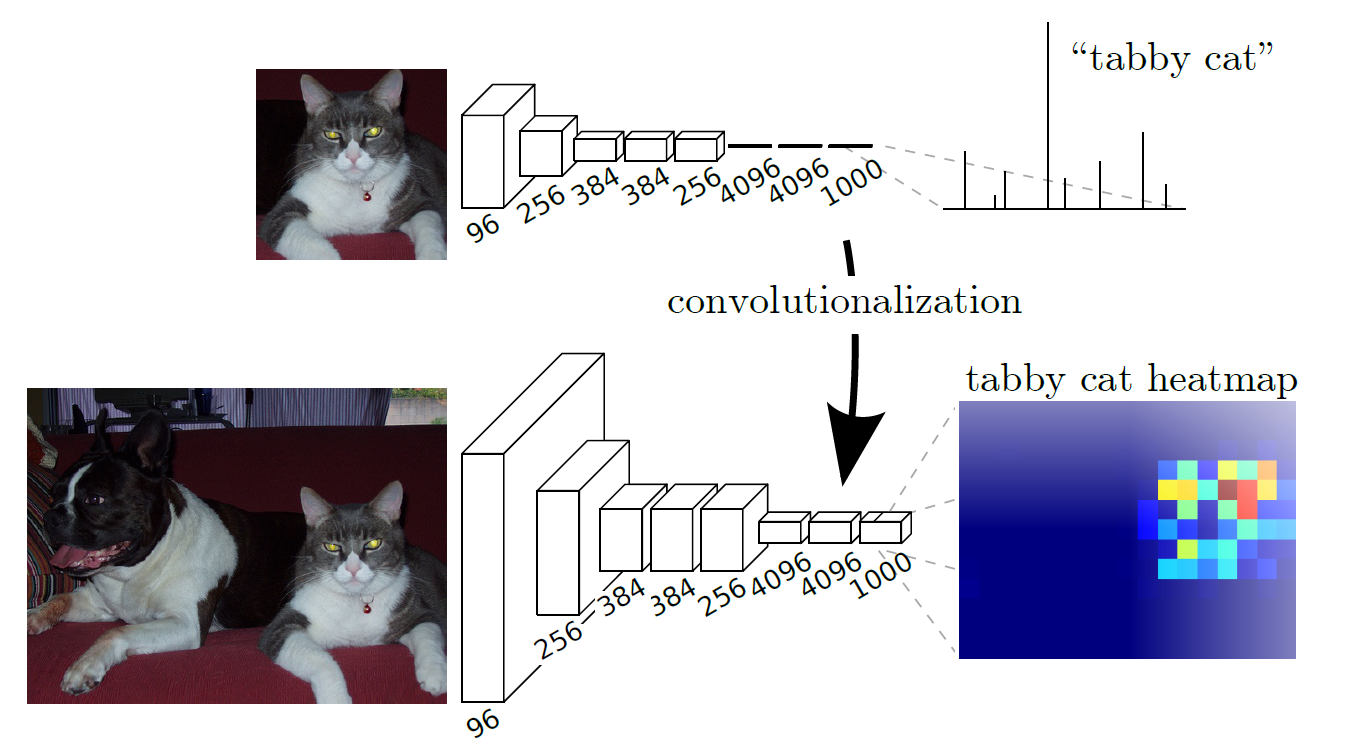
CNN 能够对图片进行分类,可是怎么样才能识别图片中特定部分的物体,在这篇论文之前,还是一个未解难题。
- 对于传统的分类网络,经过 CNN 不断卷积、池化的处理,最后进入全连接网络,预测当前图片的分类。但会丢失空间信息,无法预测每个像素的分类。
- 对于目标检测的网络,也是经过 CNN 不断卷积、池化的处理,在最后的特征图上预测类别和位置。但识别出来的是目标框,并非物体的轮廓边界。
而 FCN 的创新之处在于,使用卷积操作替换了分类网络的全连接,使得输入输出保持在相同尺寸,这样就可以预测每个像素点的类别。加上使用了卷积,自然而然也就可以处理任意尺寸的图像。网络结构如下,用下面的卷积替换上面的全连接:
上采样
经过不断的卷积,图像的尺寸会减少而维度会增加。所以为了使得网络输出的图像尺寸和原图像一致,需要进行一些上采样,使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在与输入图等大小的特征图上对每个像素进行分类,逐像素地用 softmax 分类计算损失,相当于每个像素对应一个训练样本。这部分在论文的第三章有所描述。
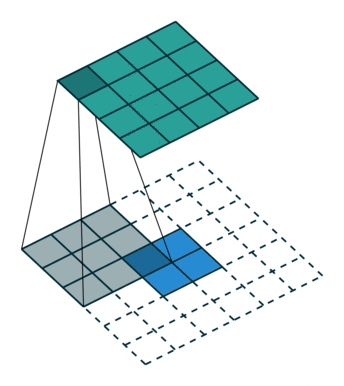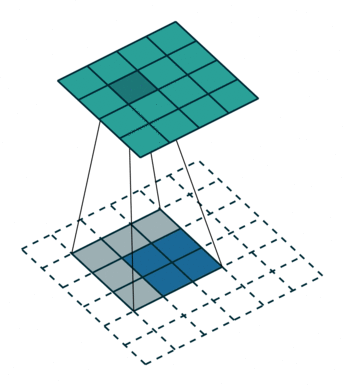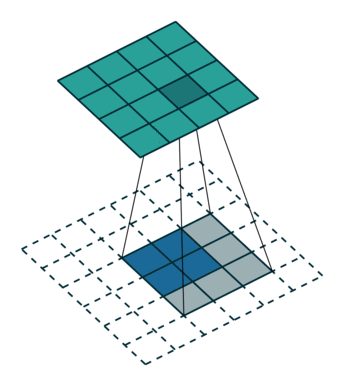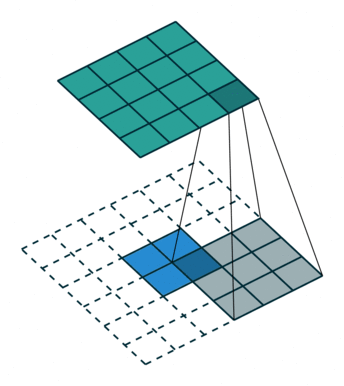
而上采样采用的操作是转置卷积,如下图 2 所示,蓝色是输入,青色是输出,将图像的尺寸瞬间增加了一倍。而文中发现,这种形式的上采样是最有效的,且,可以通过叠加之前的输入(类此残差),获得更好的精度。此外文中特意表明了转置卷积也是卷积层,按照普通的卷积层进行训练即可。
融合操作
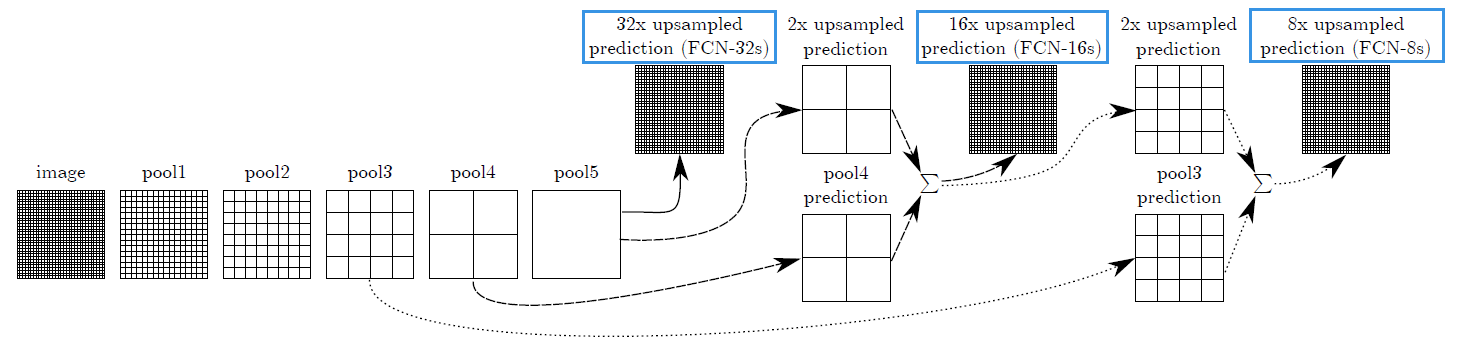
如上图所示,论文给出了 FCN 的三种版本。
- 对于 FCN-32s,直接在最后一层进行 32 倍的上采样,原始空间信息倍大量丢失
- 对于 FCN-16s,将 pool5 后的结果进行 2 倍上采样,与 pool4 的结果相加,得到结果 $F$,而后进行 16 倍上采样
- 对于 FCN-8s,将 $F$ 与 pool3 后的结果相加,而后进行 8 倍上采样
论文中的结论是,FCN-8s 的效果要好一些,毕竟更多的利用了原始空间信息。网络结构图如下 3 :
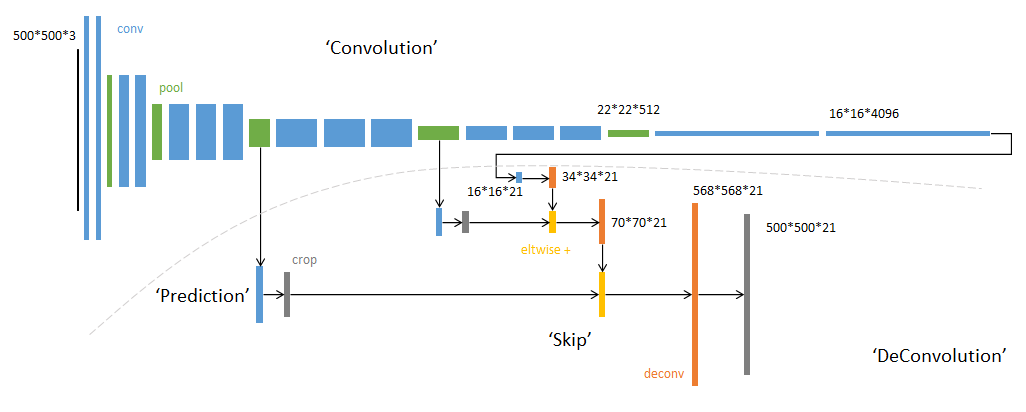
程序
网上看到了份程序,逻辑写的还不错:
https://github.com/pochih/FCN-pytorch/blob/master/python/fcn.py
尺寸在我裁剪图片的时候进行了放缩,不要太在意。

解码
若要可视化展示结果,需要对网络输出的结果进行解码。如标注图片上的类别等。假设输入图像的尺寸是 [800, 800] 的,当前类别数量是 21,会得到 [bacthsize, num_classes, height, width] 的输出。假设当前 batchsize 是 1,那么就需要在 num_classes 张 [height, width] 大小的图片中选择出每个像素点的类别。
1 | out = fcn(data)['out'] |
延伸
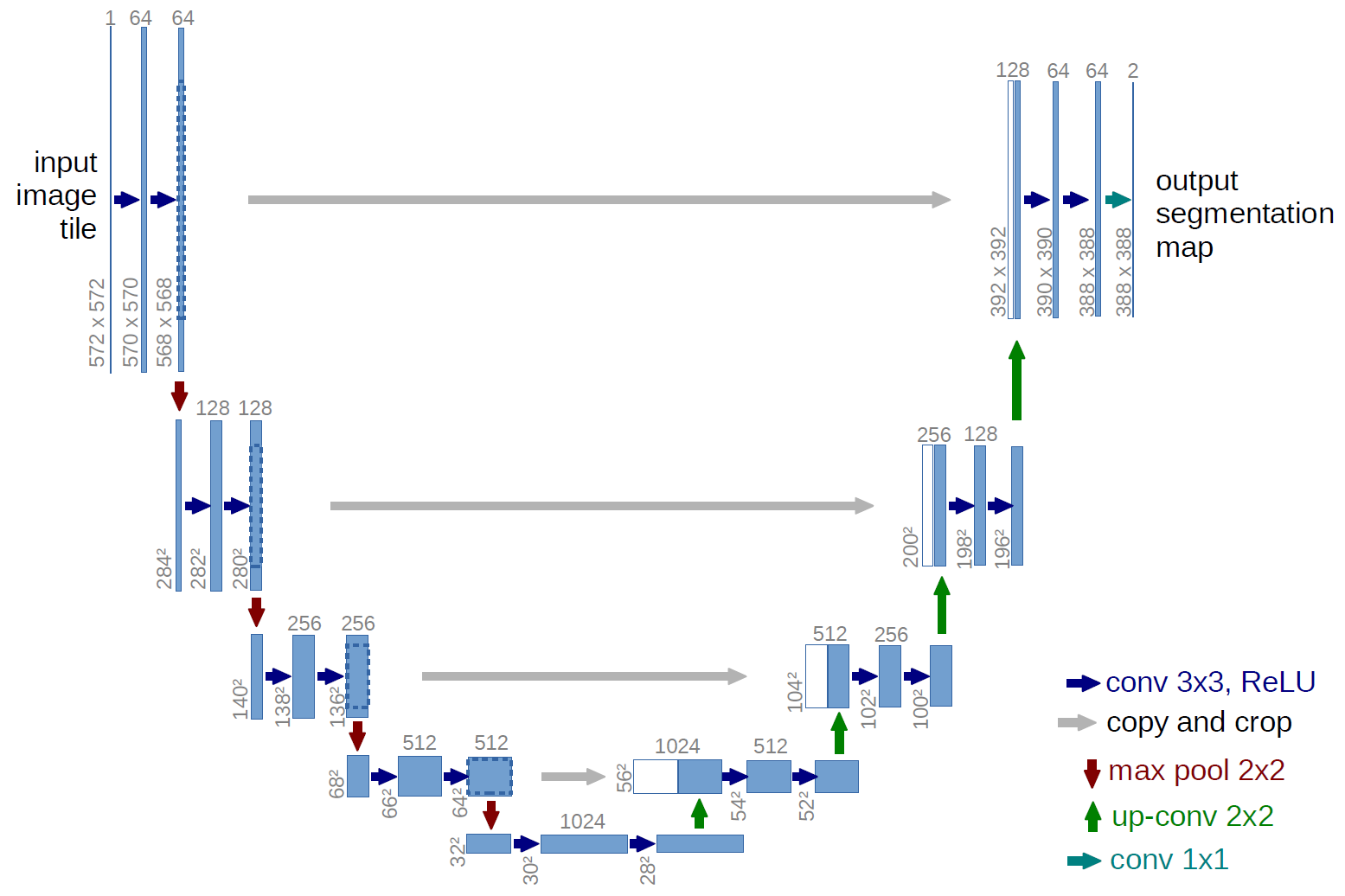
此外,U-Net 5 的网络结构也适合做分割,先记下来,也许某一天做语义分割的任务会用到。