不同于 FCN 的语义分割,Mask R-CNN 是用于实体分割的。借鉴 FCN 的思想,通过在 Faster R-CNN 的用于边界框识别分支上添加了一个并行的用于预测目标掩码的分支 Mask,在实现目标检测的同时,实现实例分割(object instance segmentation),即把每个目标像素分割出来。而 Faster R-CNN 和 FCN 在之前介绍过,所以本文的重点将会放在损失函数的设计和 ROI-Align 上。
实体分割不同于语义分割的是,不仅要检测出所属类别,还要区分同一类别下的不同实例。

按着前文描述,网络结构如下,蓝色分支是 Faster R-CNN 中用于预测类别和回归框的分支,红色分支是新加入的预测掩码的分支。
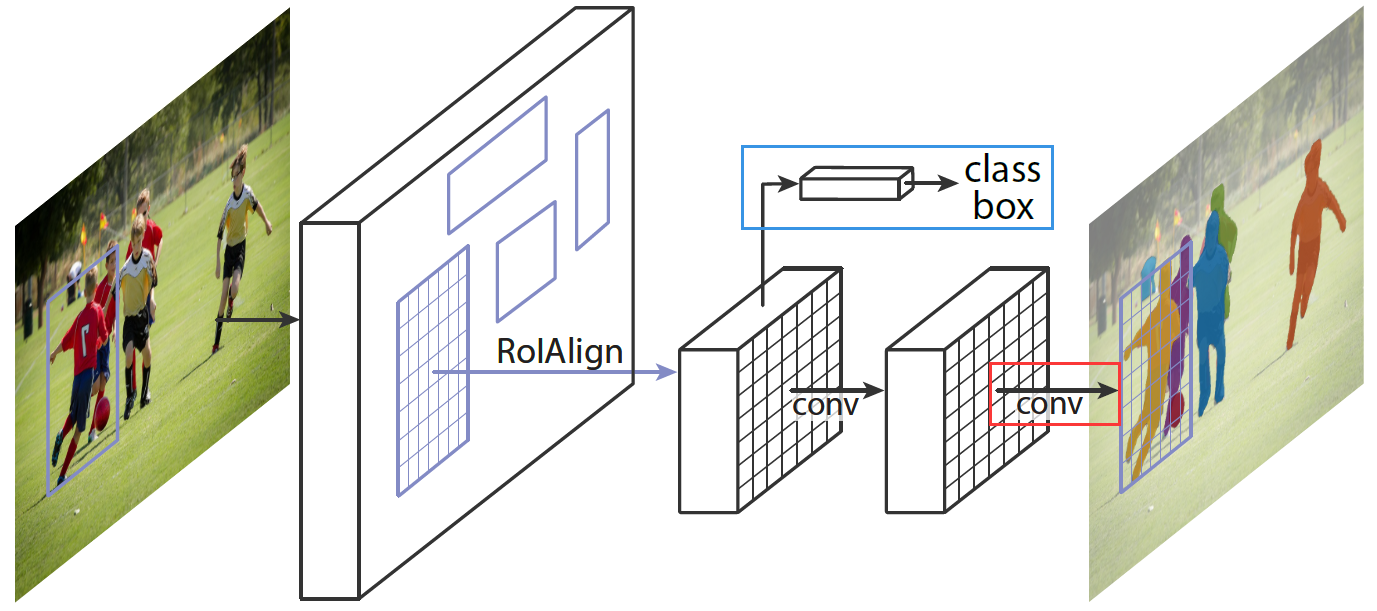
基本思想
语义分割问题只需要在语义上对像素点进行区分即可。而实例分割问题不仅需要正确地检测出所有的目标,还需要在单个目标的基础上对每一个实例进行准确的分割。而作者基于 Faster R-CNN 目标检测的框架和 FCN 的语义分割提出了 Mask R-CNN。所以流程就是:
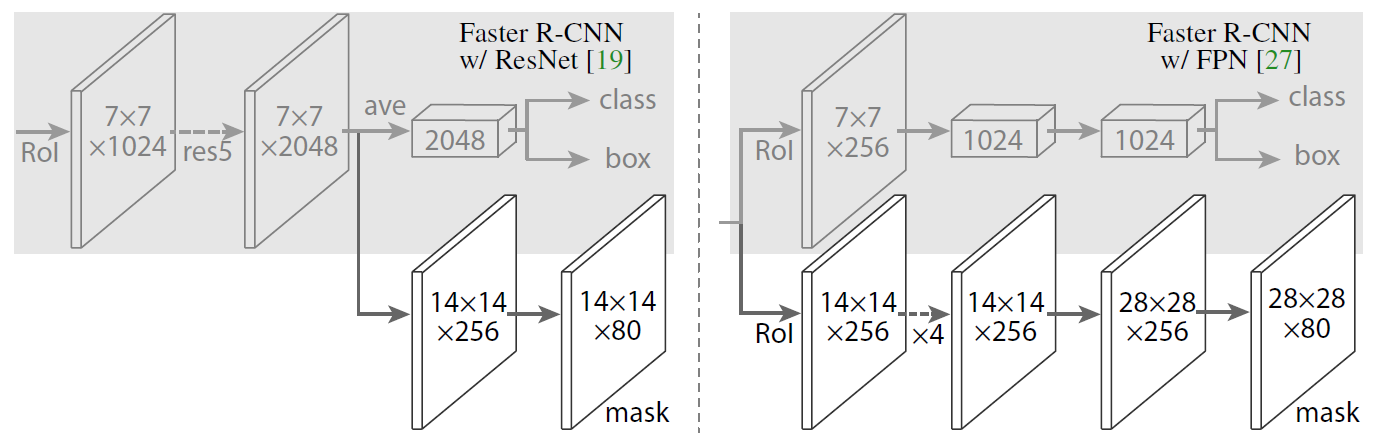
- 输入一副图片,将图片输入到特征提取层 backbone,也可以融合 FPN 机制,最终获得对应的 feature map。下图中,左图是 Mask R-CNN 和 Faster R-CNN 结合的方式,右图是 Mask R-CNN 和 FPN 结合的方式。
- 对 feature map 中获得多个候选 ROI,候选的 ROI 送入 RPN 网络进行二值分类和 bbox 回归,截止到这一步,Mask R-CNN 和 Faster R-CNN 完全相同
- Mask R-CNN 中,取消 ROI pooling,替换为 ROI-Align
- 对这些 ROI 进行分类、box 回归和 MASK 生成
如果看不懂建议重新看 Faster R-CNN 和 FCN
ROI-Align
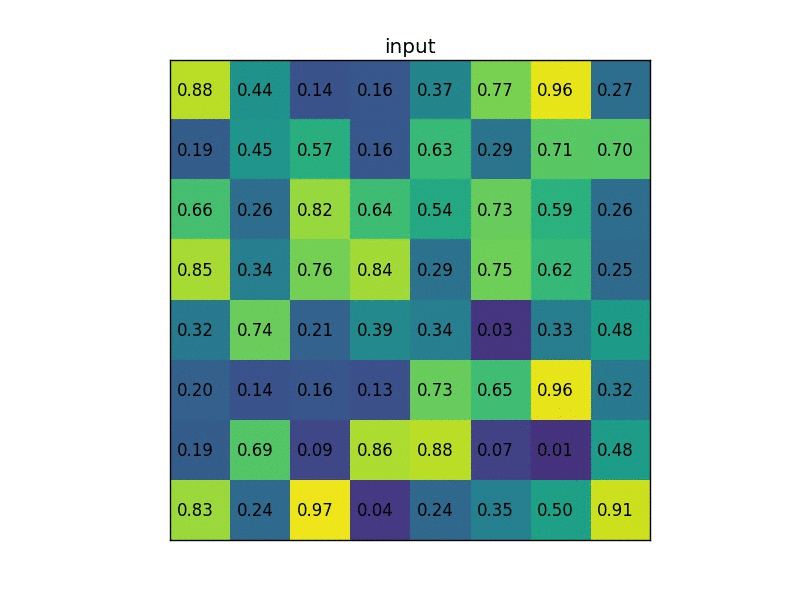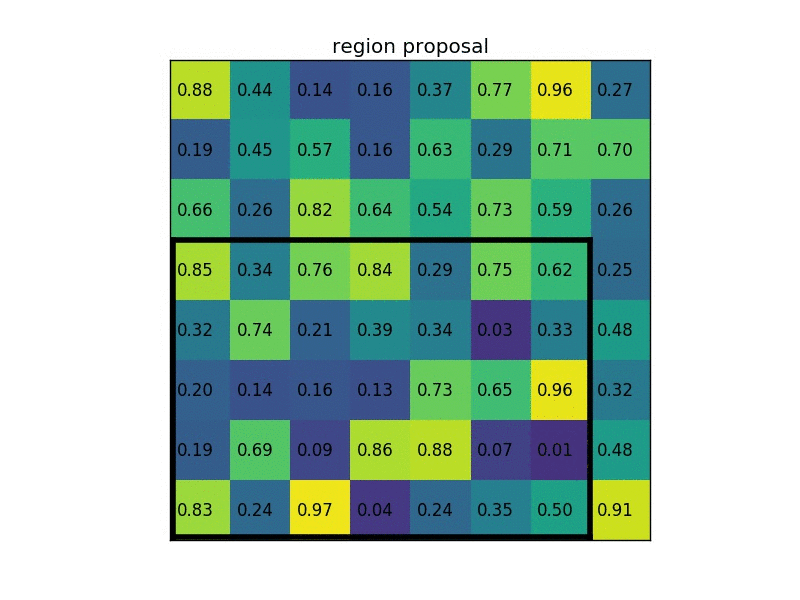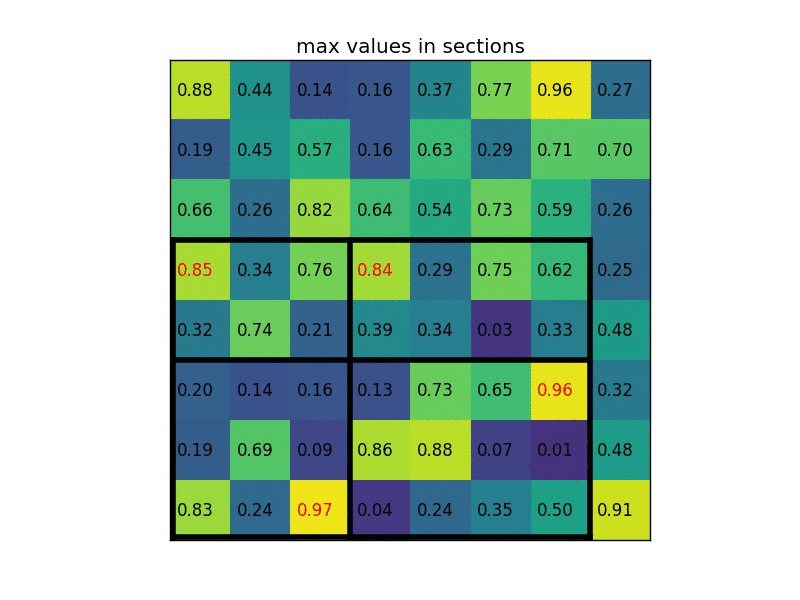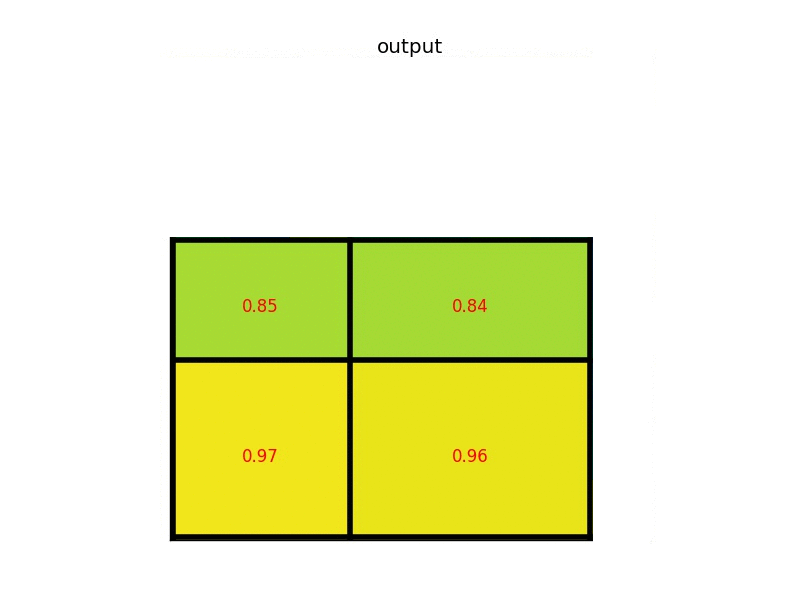
对于传统的 ROI pooling 而言,难免会有精度损失。比如 20X20 的特征图 pool 到 7X7,自然无法整除,就需要对像素点进行取舍,带来精度上的损失。RoI 对应至特征图和 ROI 进行划分这两步取整量化操作会导致 ROI 与抽取出的特征图在空间位置上不匹配。这一问题不会对目标的分类造成大的影响,但会对 mask 预测造成极大的负面影响。如下图所示 1 ,并非均匀划分:
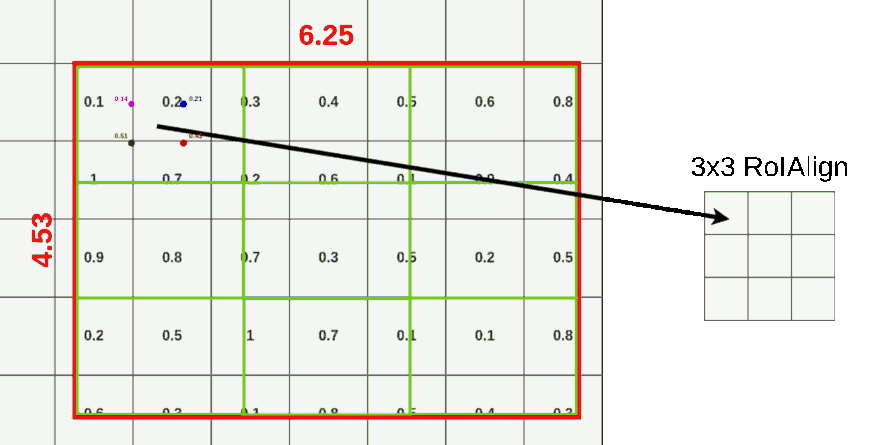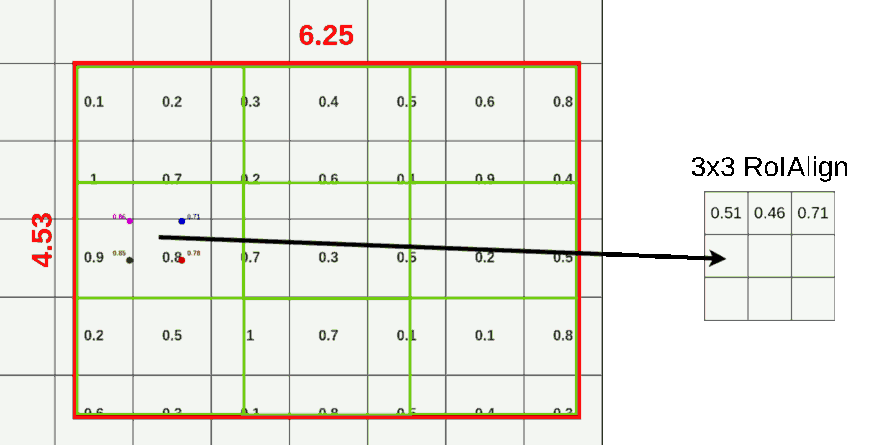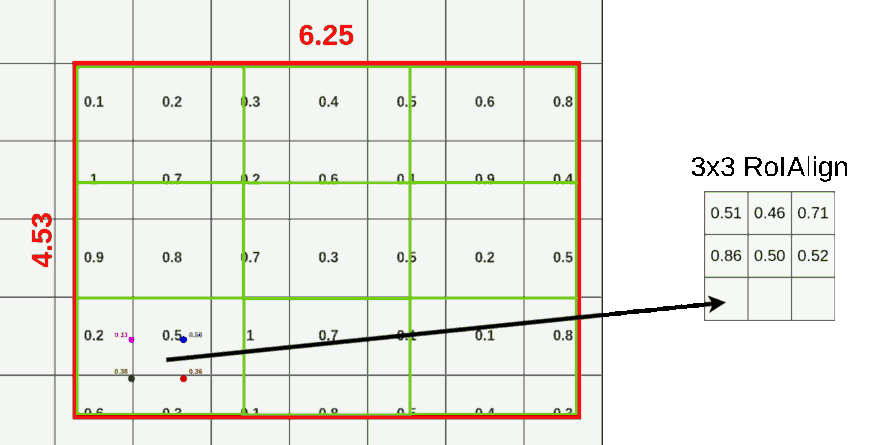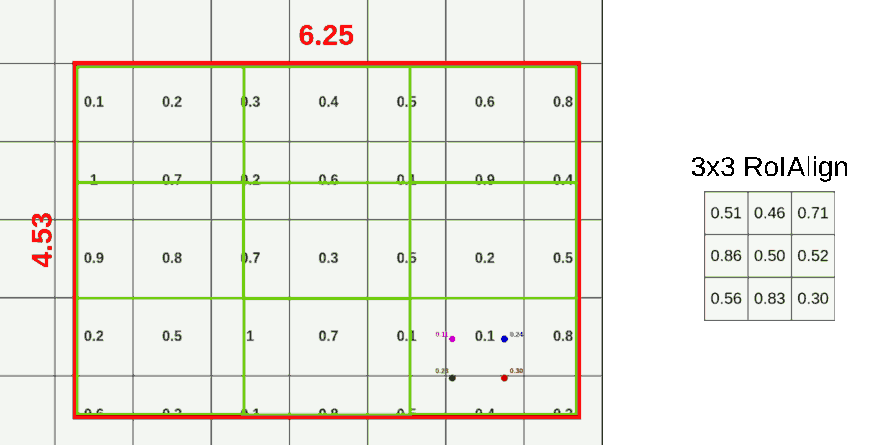
对于 ROI-Align 而言,不在对 ROI 边界进行取整。假设 pool 到 3X3 的格子,那么计算每个格子中心四个点的坐标。对于每个点而言,对每个周围的四个点进行采样,使用双线性插值计算当前点的取值,而后 max pool 获取当前格子里面的值。无论采样点的多少与采样方式,结果都不会很差。如果使用的量化取整,结果就会很差。如下图,作者也只使用了这一张图介绍了 ROI-Align。

这个过程佷繁琐不易理解,但其实并不难,可以来这篇博客看下动图。2
Mask 损失
Mask R-CNN 的分支由三部分组成,其中 $L_{\text{cls}}$ 和 $L_{\text{box}}$ 与 Faster R-CNN 没有本质区别,所以重点是 $ L_{\text{mask}}$,它是平均二分类交叉熵损失。
\begin{equation}
L = L_{\text{cls}} + L_{\text{box}} + L_{\text{mask}}
\end{equation}
假设一共有 $K$ 个类别,则 Mask 分割分支的输出维度是 $K m m$。所以对于 $m\times m$ 中的每个点,都会输出 $K$ 个二值 Mask(每个类别使用 sigmoid 输出)。这里与 FCN 的做法不同,FCN 在每个像素点上应用 softmax 函数,整体采用多任务交叉熵,这样会导致类间竞争(class competition),最终导致分割效果差。其实上文也能看到,分割效果的确很差。
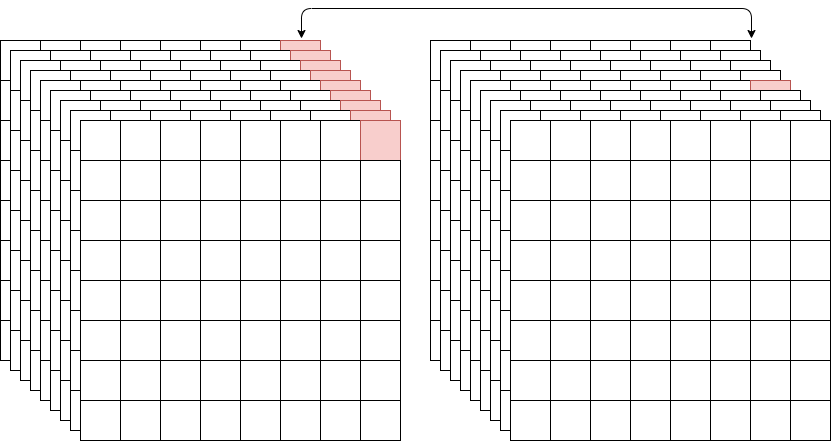
在 Faster RCNN 做 object detection 的时候,已经把某一块 RoI 识别为汽车,但这个 RoI 内可能存在其他物体的一部分,因此分割的 mask 中,除了要将汽车分割出来外,还要把另外那个物体也分割出来。这就导致这样的情况,在 object detection 的分支中,这块 RoI 整体被识别为汽车,但在 segmentation 的时候,这块 RoI 一部分被识别为汽车,一部分又要当作其他物体。如此一来,这两个分支回传到前面的梯度多少存在冲突,而前面的特征提取网络可是共享的,结果网络在学习的时候就可能出现左右为难的情况。
那么来考虑二分类。To this we apply a per-pixel sigmoid, and define $L_{\text{mask}}$ as the average binary cross-entropy loss. For an RoI associated with ground-truth class $k$, $L_{\text{mask}}$ is only defined on the $k$-th mask (other mask outputs do not contribute to the loss). 也就是,只考虑一种类别,如果 ground truth 中标记了这个 bounding box 中是个人的话,那我们就只针对人的 mask 进行分割,而对这个 bounding box 中其他可能存在的物体一律忽视。如下图所示。这里画图的思想参考了这篇文章 3。
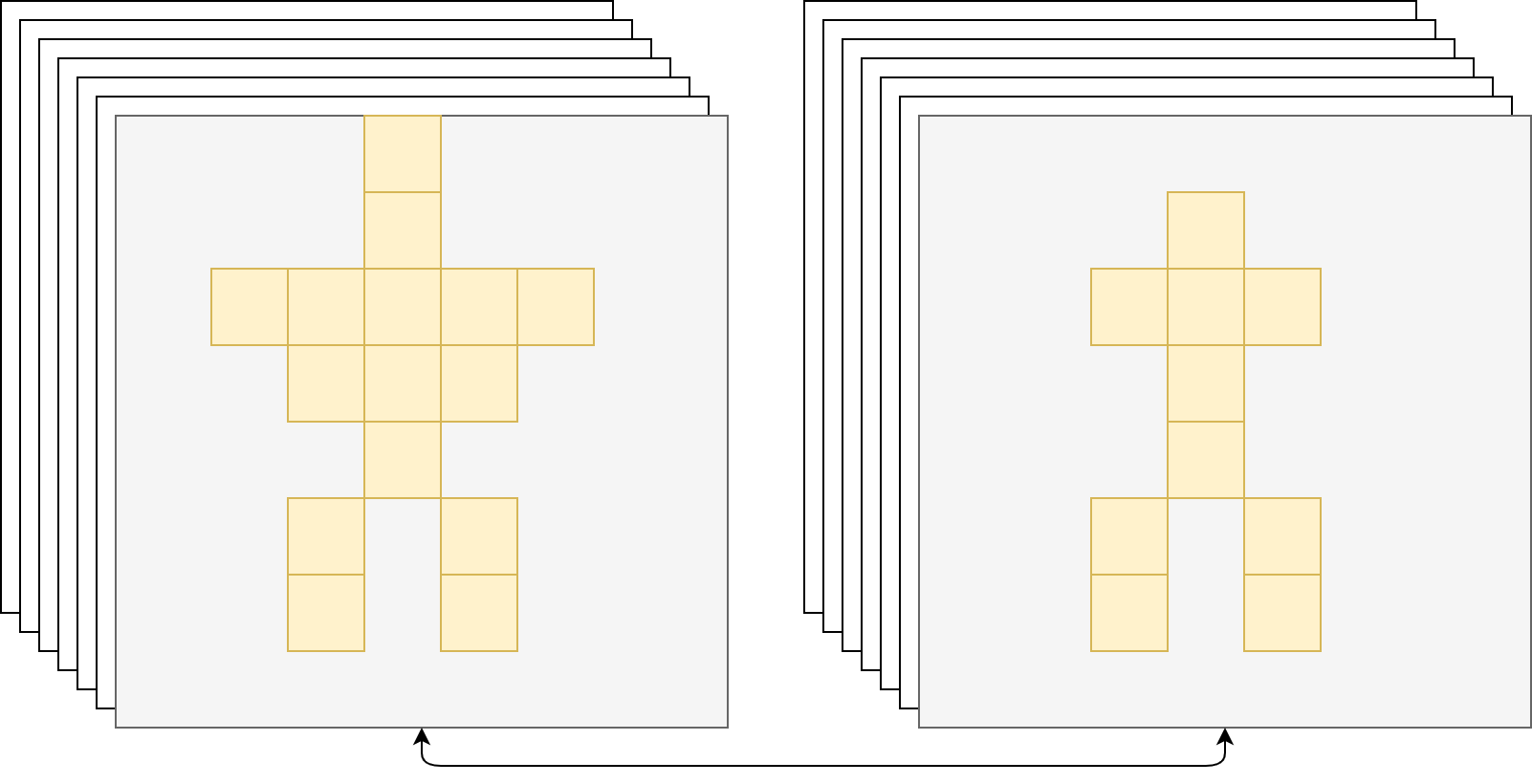
在测试阶段,通过分类分支预测的类别来选择相应的 Mask 预测。这样,Mask 预测和分类预测就彻底解耦了。
程序
- torchvision 上有现成的示例。
- 等我以后用到语义分割的时候再回来补冲这里的程序,那时候肯定是 open-mmlab 系列的东西了。

