书接上文,因为参加 NLP 的比赛不知道什么是 bert 实在有点说不过去,于是花了三天时间看了下 bert 的基本概念和代码。不得不说,网上阳间的 bert 预训练代码太少了,大多是转载和 mark 之类没啥用的东西,属实是占据了搜索引擎的首页,占够了热度。
transformer
这个就不得不提一下 Attention is all your need. 由于处理序列的时候 RNN 不容易并行计算,输出 $b_4$ 的时候需要输入 $a_1, a_2, a_3, a_4$。所以使用 CNN 来代替 RNN,一个 CNN 按顺序划过序列输入产生一个输出,就不用看完一个句子才会有输出,而多个 CNN 就可以产生多个输出,模型就可以可以并行化。如下图所示,不需要等待红色的输出算完,再算黄色的输出。
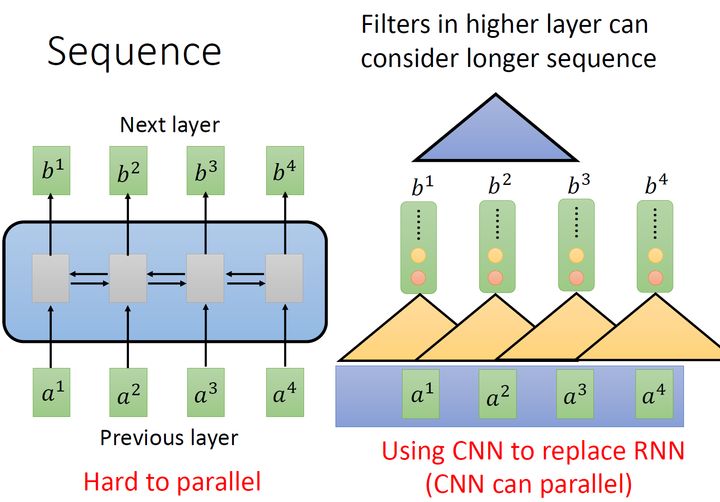
如果考虑让一个 CNN 看到更多的输入,那么只需要在模型的隐层叠加另外的 CNN 即可,也就是上图的蓝色三角。基于这个概念,就有了后面的 self-attention。
self-attention
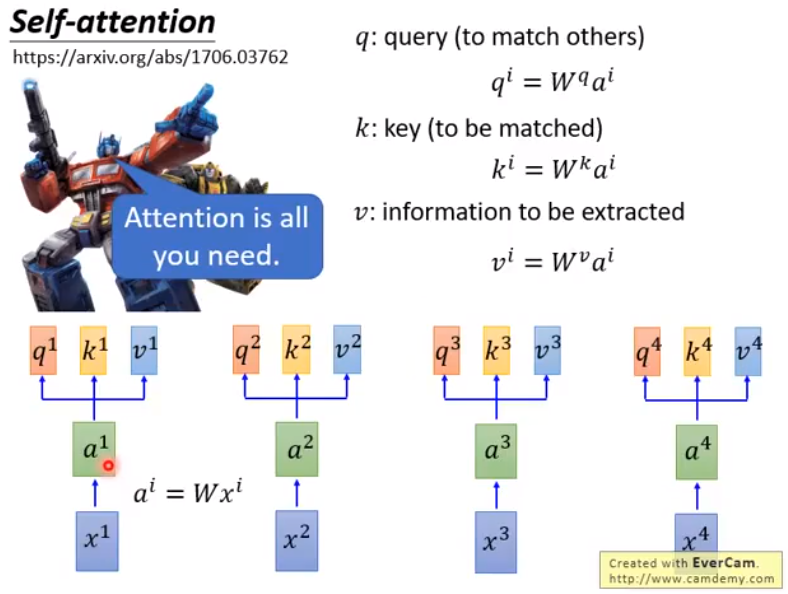
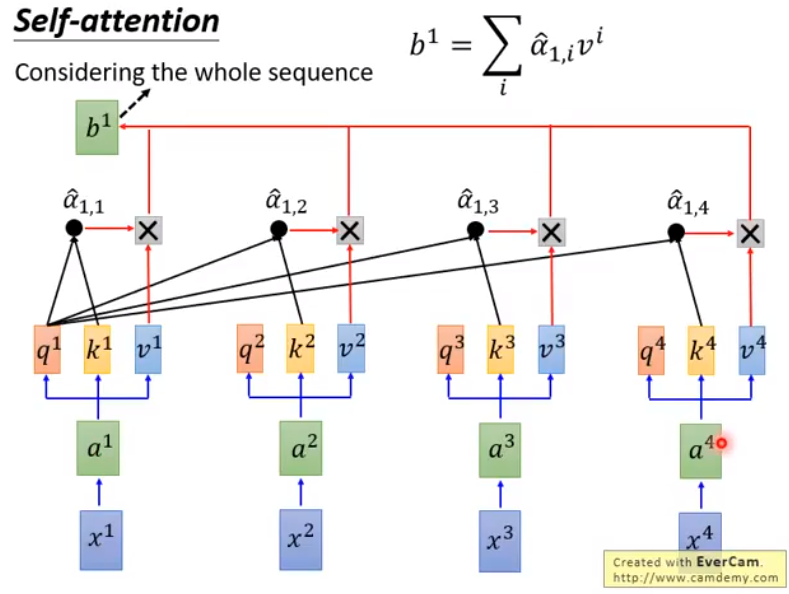
$A=Wx, Q=W_qA, K=W_kA, V=W_vA$,这里其实就是乘以一个大矩阵,只不过图里分开写清楚一些。
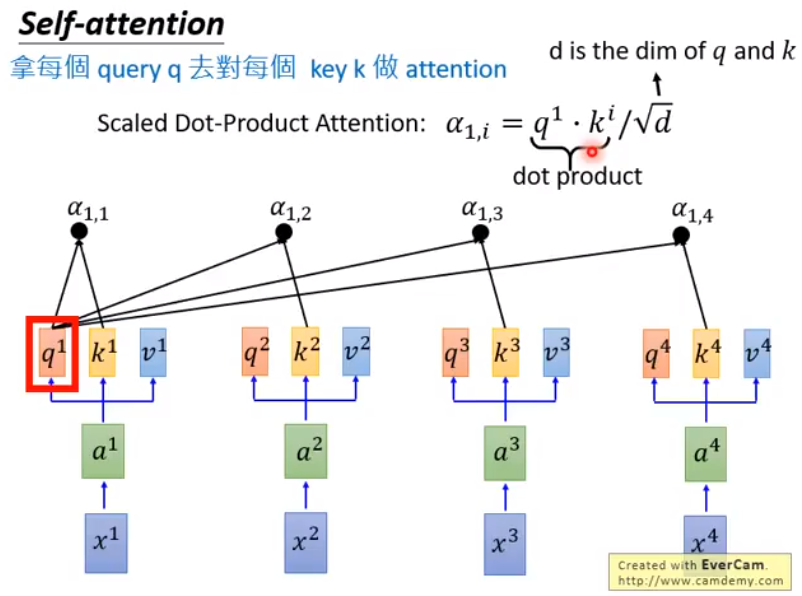
之后每个 $q$ 和每个 $k$ 做 attention,也就是内积,得到如下的 $\alpha$ 输出,然后再除以维度数,防止维度过高导致的内积过大。
然后将 $\alpha$ 经过 softmax 操作得到 $\hat{\alpha}$:
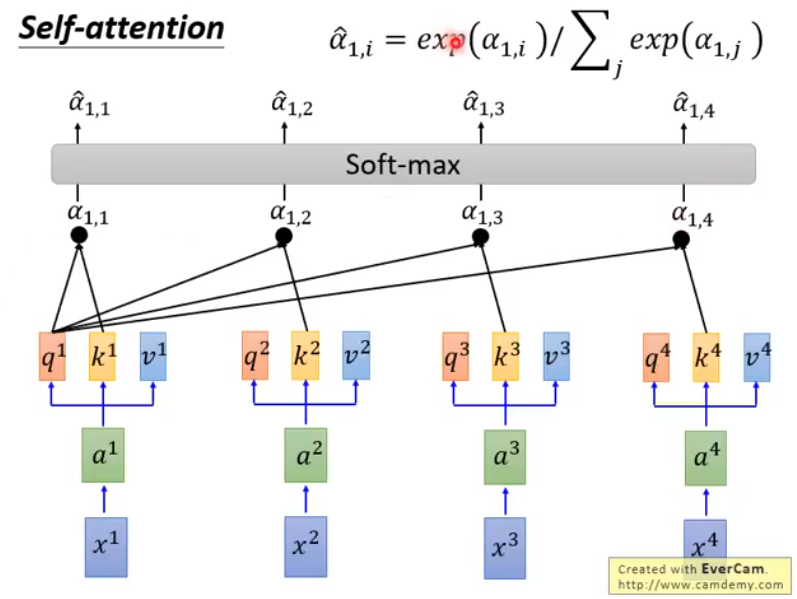
对于 $b_1$ 输出,只需要让 $\hat{\alpha_{1,i}}$ 和所有的 $v_i$ 做乘积并求和即可。同理,可以得到 $b_2,b_3,b_4$ 的输出。
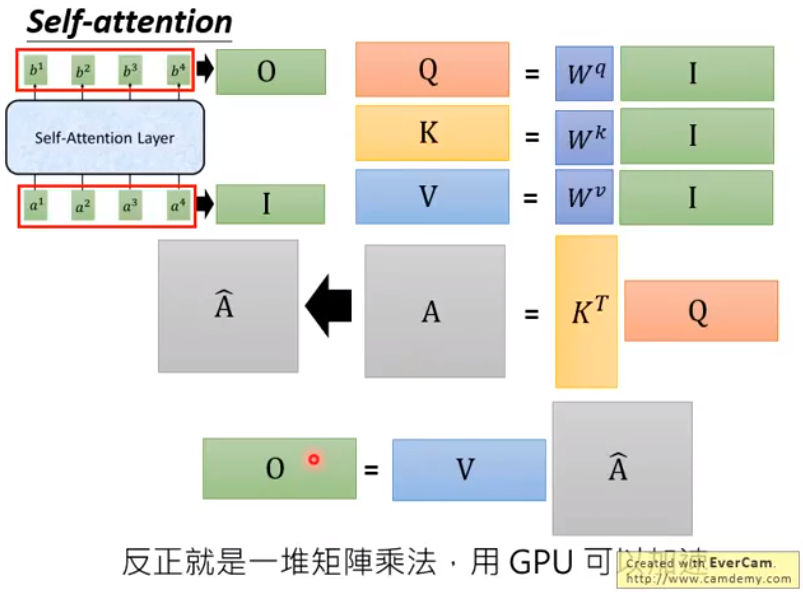
对应的,下图左上角就是我们的 self-attention 层,期中的运算可以总结成矩阵乘法:
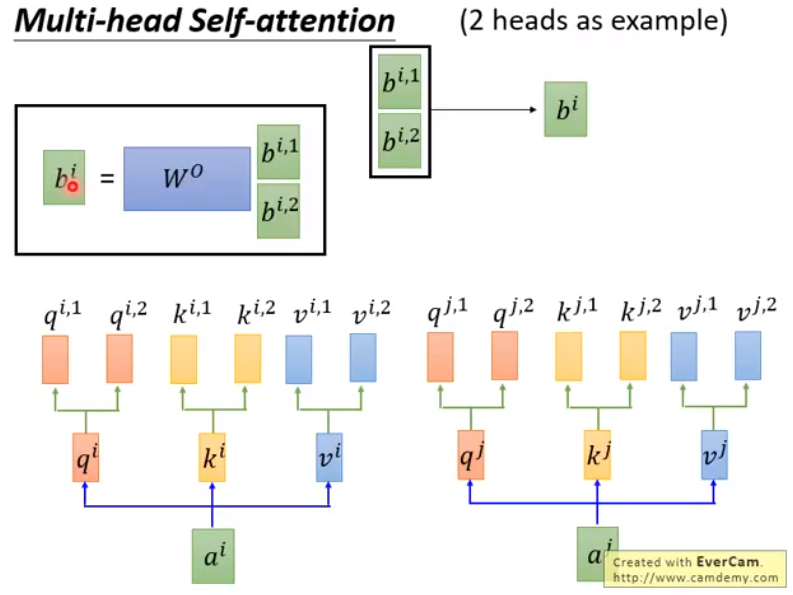
multi-head-self-attention
可以再计算 $Q,K,V$ 的时候产生多个结果,然后在输出 $b$ 的时候再通过一个矩阵将多个结果融合成一个。而我看的程序,就分开注意力,最后 view 到一起。
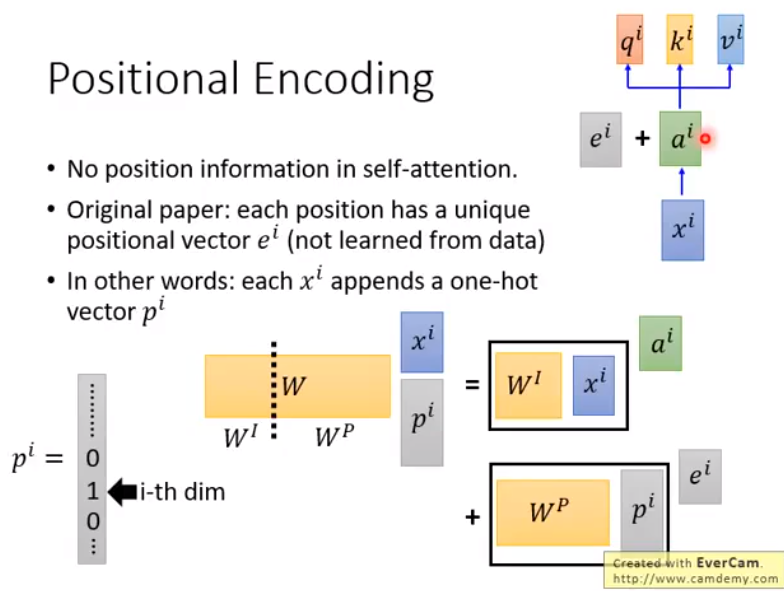
Positional Encoding
现在的 self-attention 没有考虑到序列的位置信息,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于 NLP 来说非常重要,所以需要加入位置的 embedding。人工设定每一个位置的 embedding,和 $A$ 加在一起作为新的 $A$ 参与后面的运算,等价于在 $X$ 拼接一个 one-hot 向量后再做运算:
程序
网上最常见的图就是它了,在看完理论后还是由些许的疑惑之处,比如位置编码如何实现,比如注意力机制具体如何执行,只能看代码来解决。
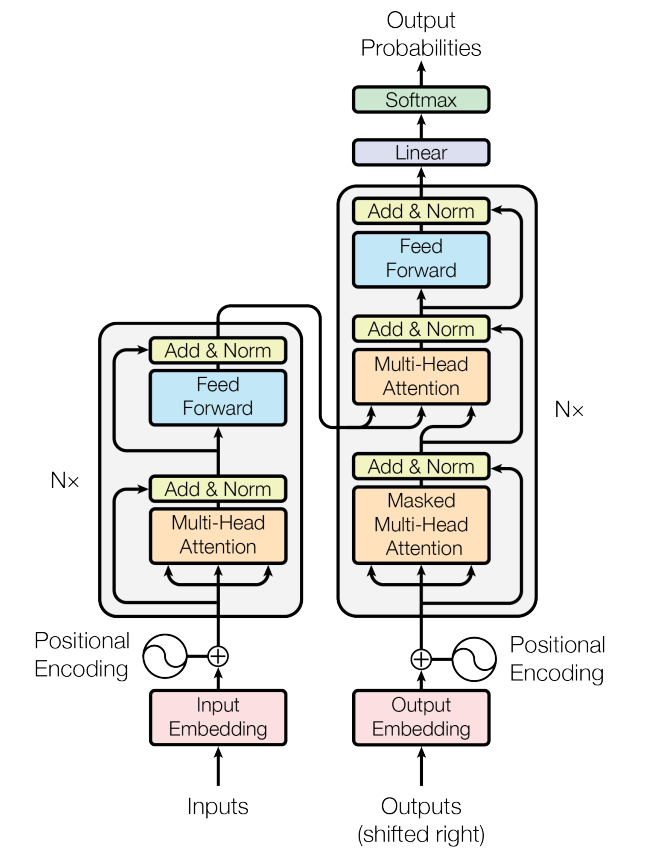
MultiHeadAttention
- 在这个类的初始化阶段,首先初始化 $W_Q,W_K,W_V$ 三个全连接层,输入维度和输出维度保持一致。假设输入维度是 512,有 8 个头;
- 计算 $Q,K,V$,大小是
B, L, 8, 64,毕竟有 8 个头。在 softmax 之后经过 0.1 的 dropout,最后在把这 8 个头 view 到一起,加上最开始的 $Q$
FeedForwardNetwork
- 经过全连接降维,而后 relu 激活并 dropout
- 在经过一个全连接,升到之前的维度,加上最开始的输入做一个残差,layer norm 后输出
PositionalEncoding
这个就是生成一个 $200\times dim$ 的表,每次输入一个 $x$,查看 $x$ 的维度,从表中取到对应维度的数值,和 $A$ 直接相加。这个表采用的是 sin-cos 规则,使用了 sin 和 cos 函数的线性变换来提供给模型位置信息。
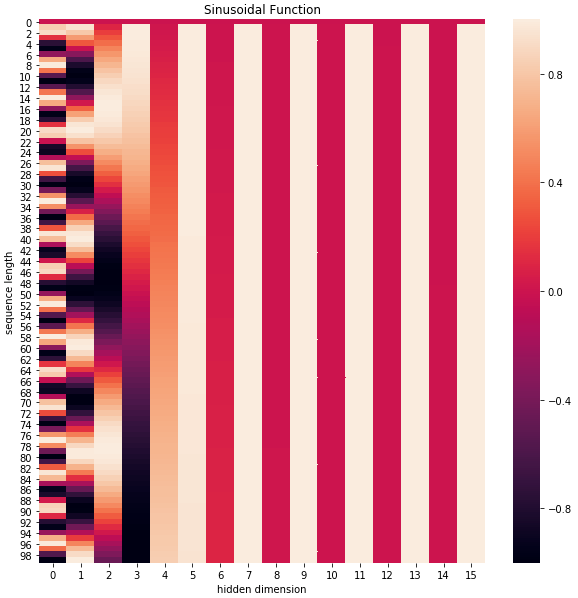
如上图所示,随着维度越来越大,周期变化会越来越慢,而产生一种包含位置信息的纹理。
Encoder Layer
- 输入 $x$ 经过 layer norm,经过 MultiHeadAttention,经过 dropout 得到 $y$,进行 $x+y$
- 将 $x+y$ 经过 layer norm,经过 FeedForwardNetwork,经过 dropout 得到 $y’$,最终的输出为 $x+y+y’$
通常,这个 Encoder Layer 堆叠 6 次 (因为维度没有发生变化)得到 Encoder。Encoder 的输入是输入序列的 embedding,如果是最开始的输入,需要叠加位置 embedding 后 dropout->layer norm,在经过堆叠的 Encoder Layer。
Decoder Layer
大部分内容和 Encoder Layer 一样,先将 target 进行 embedding 并叠加位置 embedding,然后 dropout->layer norm,得到解码输出。拿到 encoder 的输出和解码输出送入 decoder,再依次经过堆叠的 6 个 decoder layer 时(解码输出注意力机制,结果在和encoder 输出进行注意力)得到新的解码输出,上一个解码状态输出下一个状态的解码输入。
在拿到 decoder 的输出后,经过一个全连接层,将 dim 映射到 n_vocab。而 bert 的结构就是 transformer 的多个 Encoder 双向堆叠到一起:
其输入的 embedding 为:
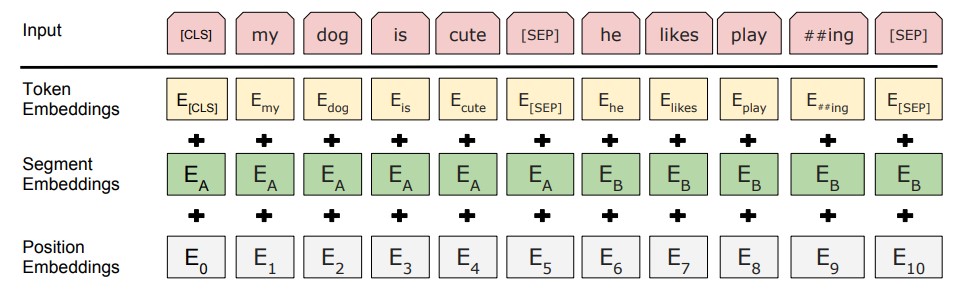
- Token Embeddings 是词向量,第一个单词是CLS标志,可以用于之后的分类任务,通过 embedding 层实现。如果句子很短,pad 为 0。
- Segment Embeddings 用来区别两种句子,因为预训练还要做 NSP 任务,同样是 embedding 层。
- Position Embeddings 和之前的 Transformer 不一样,不是三角函数而是学习出来的,非人工设定,而是 embedding 层。
将这三者的相加作为输入,经过 layernorm 和 dropout 后输出。大概理论就是这些,不过它的预训练是真的靠谱,或者说,应用到具体任务,可以针对具体任务设计与训练。借着预训练,解释一下上面的符号,也是困扰我很久的东西。
之前一直不知道 CLS 这种东西是干什么的,直到看了代码才清楚,这个符号输入网络,最后一层的输出经过全连接和激活,得到的输出,所以这个符号对应位置的输出能用于下游分类任务。
此外,常用 bert 训练时会传入三个参数,input_ids 表示输入序列的原始 token id,即根据词表映射后的索引,token_type_ids 用于不同序列之间的分割,例如 [0,0,0,0,1,1,1,1] 用于区分前后不同的两个句子,形状为 [src_len,batch_size]。而最重要的 mask 值得细说:
MASK
bert 有效的原因取决于它的预训练,比如 MLM(Mask language model) 和 NSP (Next sentence prediction),而这其中依赖的主要是 mask。
处理非定长序列
在NLP中,文本一般是不定长的,所以在进行 batch训练之前,要先进行长度的统一,过长的句子可以通过truncating 截断到固定的长度,过短的句子可以通过 padding 增加到固定的长度,但是 padding 对应的字符只是为了统一长度,并没有实际的价值,因此希望在之后的计算中屏蔽它们,这时候就需要 Mask。此外,self-attention中,$Q$ 和 $K$ 在点积之后,需要先经过 mask 再进行 softmax,因此,对于要屏蔽的部分,mask之后的输出需要为负无穷,这样softmax之后输出才为0。
辅助预训练
做 MLM 预训练时,需要对句子进行 mask,使得模型看不到输入句子的单词。而后,其 label 为被 mask 掉单词的 id。由于 bert 本身的结构,由于预训练的时候,需要做 NSP 和 MLM,而 NSP 是二分类任务,MLM 是多分类任务,因此需要在 bert 上插入两个头分别实现这两个功能,前者就是将缺失的词汇预测回去,后者加入一个全连接输入 pooler output,判断句子是否为上下文。

